



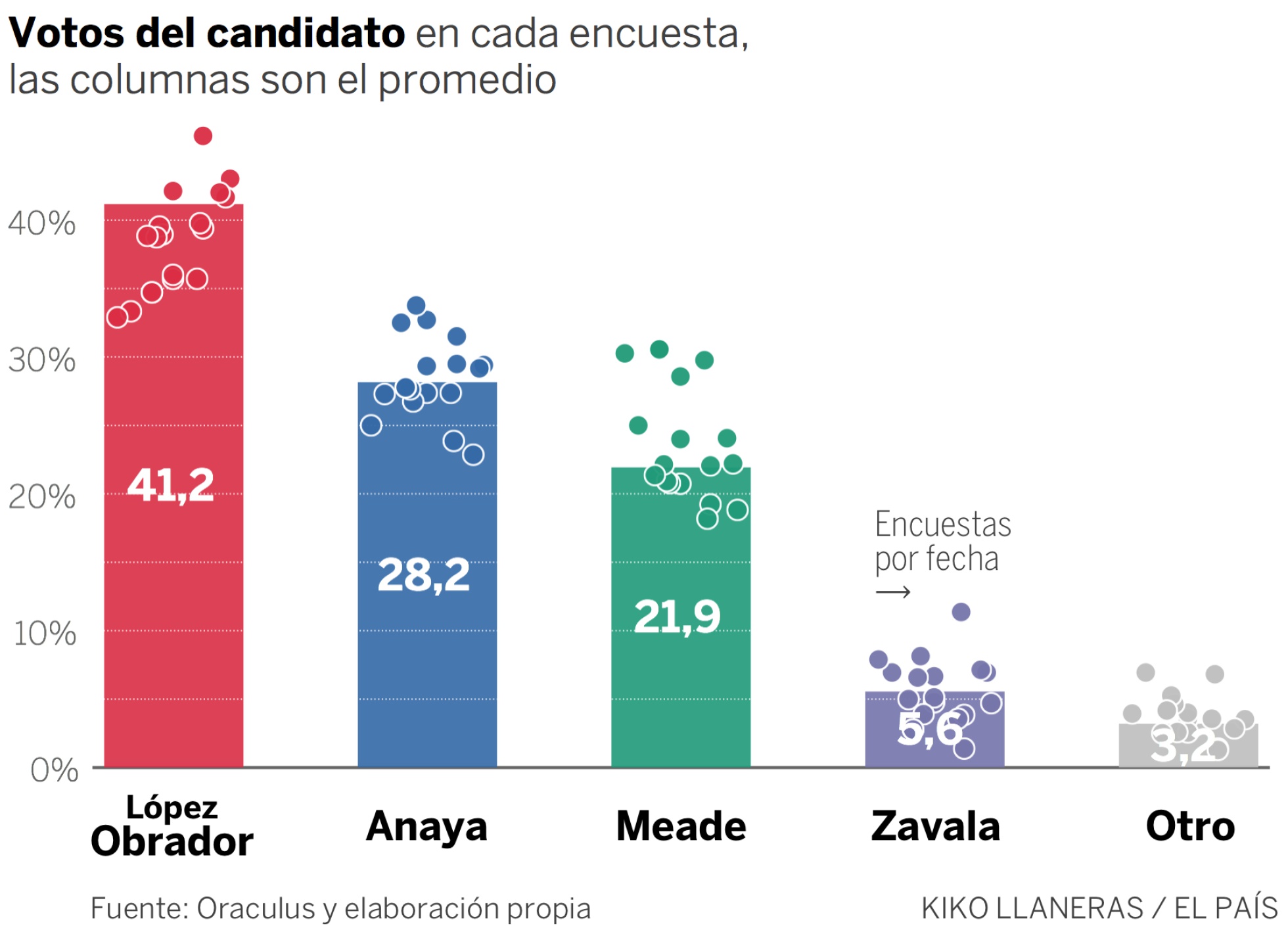
La primera predicción electoral de EL PAÍS coloca al líder de Morena como presidente más probable (79%), seguido de Ricardo Anaya (16%) y José Antonio Meade (5%)
El promedio de encuestas coloca delante a Andrés Manuel López Obrador, con un 41% de los votos, seguido de Ricardo Anaya (28%) y José Antonio Meade (22%). Faltan todavía tres meses hasta la votación presidencial, pero el candidato de Morena cuenta con 14 puntos de ventaja y es, a día de hoy, un favorito claro.
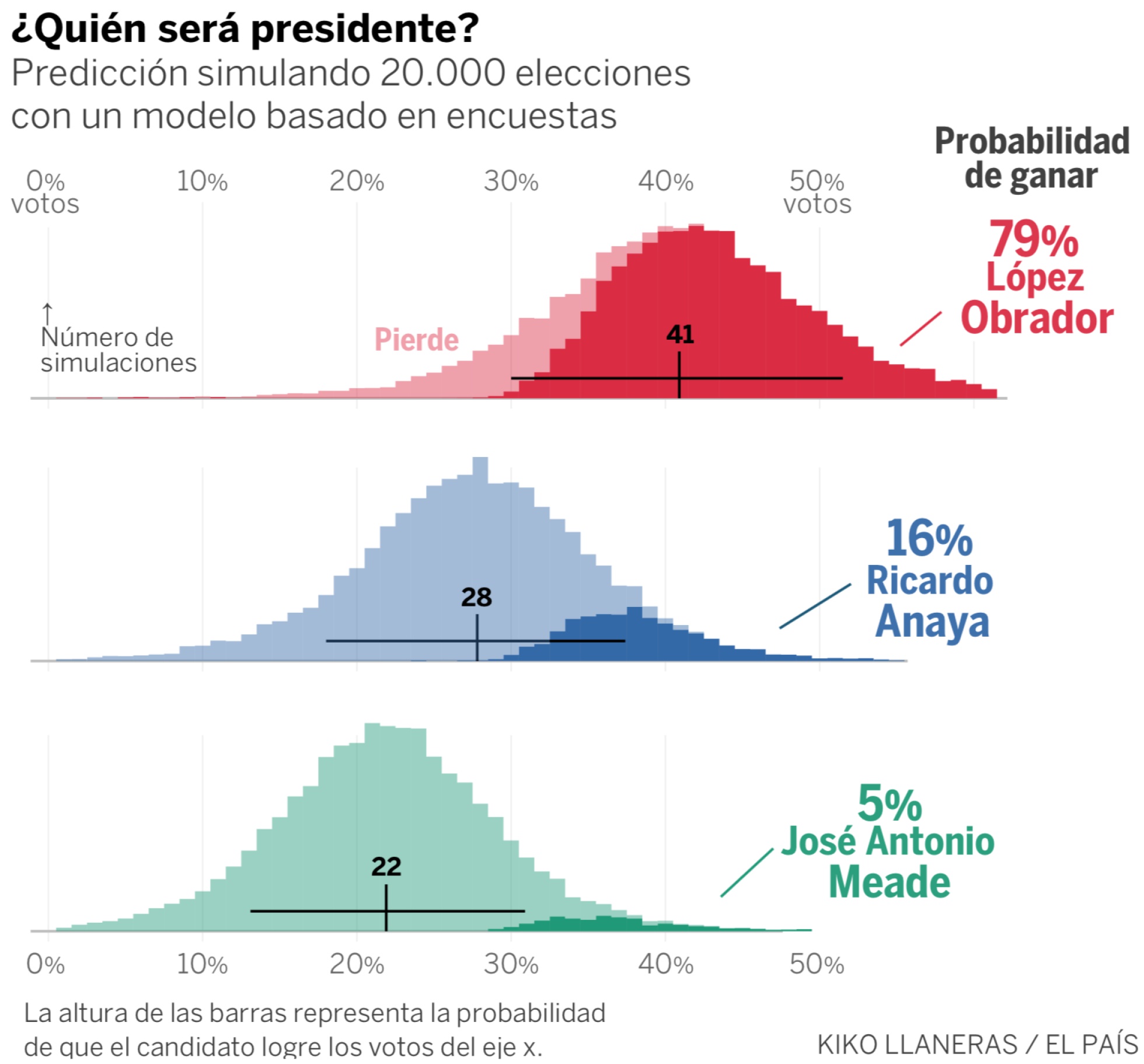
Es importante interpretar bien estas probabilidades y la incertidumbre que representan. La victoria de López Obrador es casi tan probable como lanzar un dado y evitar el seis. Pero eso no es una certeza, como sabe cualquier que haya tirado un dado. Sirve de referencia una estadística deportiva: la derrota de López Obrador sería tan probable como ver fallar un penalti.
Estos pronósticos se calculan a partir de encuestas, usando la metodología de nuestros modelos electorales para Francia, Reino Unido o España (ver detalles al final). Estos modelos convierten las encuestas en predicciones después de estudiar su precisión histórica. ¿De qué magnitud son los errores habituales? ¿Cómo de probable es que se produzcan fallos de 3, 5 o 15 puntos? Para responder esas preguntas hemos analizado decenas de encuestas en México, y más de 4.000 en otros países.
El acierto de los sondeos en México
Los sondeos estuvieron razonablemente bien en las elecciones presidenciales de 2012 y 2006 —y aún mejor en las federales de 2015 y 2009—, pero se desviaron mucho del resultado en el año 2000. En las tres últimas presidenciales, el error medio del promedio de sondeos ha sido de 3 puntos por candidato. Eso significa que fueron habituales desviaciones de 3 o 4 puntos y que el margen de error rondó los 8 puntos. Es una precisión razonable, que no se aleja mucho de la que consiguen las encuestas en países como EEUU o España.
Pero tres elecciones son pocas para extraer conclusiones fuertes, especialmente si miramos el acierto de los sondeos en la región: un análisis de 24 votaciones en Latinoamérica eleva el error medio a casi 4 puntos. Por eso, queriendo ser cautos, nuestro modelo asume un error medio de 3,5 puntos para México. Además, quedan todavía tres meses hasta la votación y eso añade incertidumbre, de forma que el margen de error hoy supera los 17 puntos para un candidato con el 35% de votos. De ahí que López Obrador sea favorito con ese 79% de probabilidad.
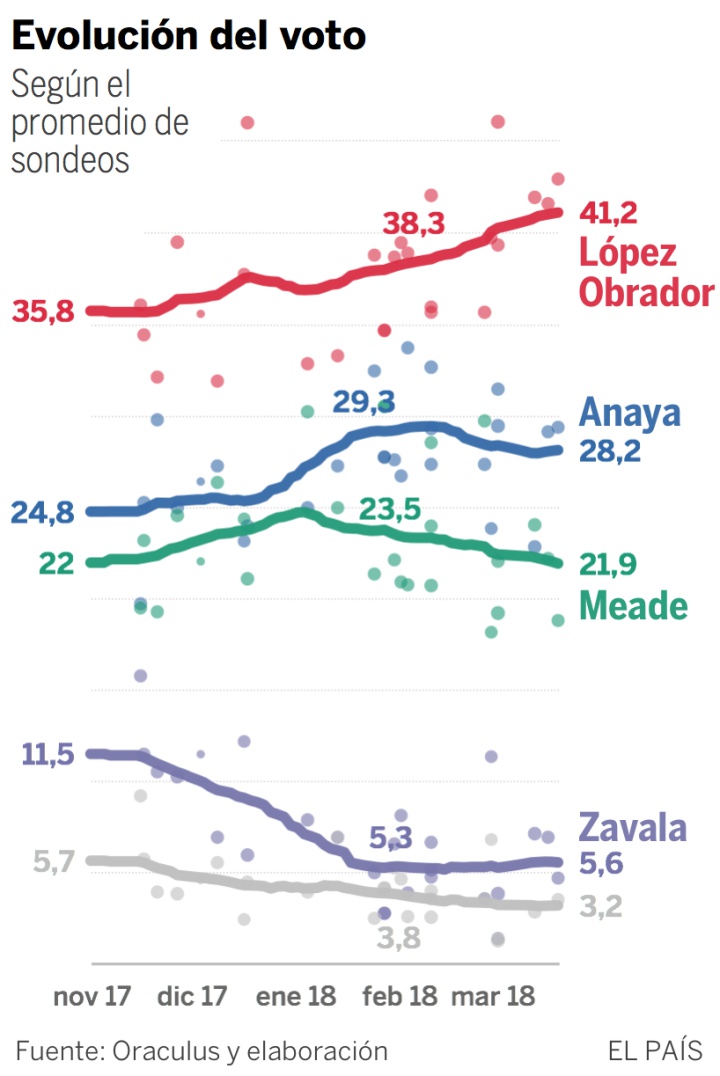
En las próximas semanas los sondeos ganarán precisión y será clave ver cómo evoluciona cada candidato. De momento en estos meses ha habido dos movimientos. El primero fue la progresión de Anaya, que empezó el año hacia arriba, colocándose segundo y distanciando a Meade con claridad, pero cuya escalada se truncó en marzo, rodeado de denuncias de corrupción. Desde entonces el candidato del Frente ha perdido un par de puntos porcentuales, aunque no más.
La otra tendencia es la paulatina subida de López Obrador, que desde otoño ha pasado del 36% al 41% de voto estimado. No es la única buena noticia para el candidato de Morena. A su favor está la evolución de los indecisos. Como reportan desde Oraculus.mx, el porcentaje de no respuesta ha bajado del 25% al 21%. Hay todavía muchas personas en México que no se decantan por ningún candidato, pero su número se ha reducido sin perjudicar, de momento, las fuerzas de López Obrador.
Metodología del modelo. Las predicciones las produce un modelo estadístico basado en sondeos y en su precisión histórica. El modelo es similar al que usamos en Francia, Reino Unido o Cataluña. Funciona en tres pasos: 1) agregar y promediar las encuestas en México, 2) incorporar la incertidumbre esperada, y 3) simular 20.000 elecciones presidenciales para calcular probabilidades.
Paso 1. Promediar las encuestas. Nuestro promedio tienen en cuenta docenas de sondeos para mejorar su precisión. Los datos han sido recopilados en su mayoría por la web Oraculus.mx. El promedio está ponderado para dar distinto peso a cada encuesta según tres factores: el tamaño de la muestra, la casa encuestadora y la fecha.
Peso por muestra. Las encuestas con más entrevistas reciben más peso, según una ley decreciente (pasado cierto umbral, hacer más entrevistas aporta poco).
Efecto de la casa encuestadora. La mayoría de encuestadoras tienden a dar mejores resultados a un candidato de forma sistemática. Es algo razonable: si usan métodos e hipótesis diferentes, es normal que sus desviaciones sean constantes. El problema es que estos efectos mueven el promedio artificialmente a corto plazo. Una opción para evitarlo es calcular los «efectos casa», la desviación sistemática de cada encuestadora con cada candidato. Después, al promediar las encuestas, sustraemos (parte de) esa desviación del dato de la encuestadora.
Encuestas repetidas. Ponderamos a la baja las encuestas repetidas de un mismo encuestador. La idea es sencilla: no queremos que una empresa que haga muchas encuestas domine el promedio. Al calcular el promedio en una fecha, la encuesta más cercana de cada encuestador tiene peso 1, y el resto un peso reducido.
Peso por fecha. El último factor es el más importante: queremos dar más peso a las encuestas recientes al calcular el promedio. Para conseguir eso asignamos pesos a los sondeos según una ley decreciente exponencial (por ejemplo, en este promedio una encuesta de hace 15 días recibe la mitad de peso que una encuesta de hoy). También definimos una franja de exclusión y eliminamos completamente las encuestas con más de 60 días de antigüedad.
Paso 2. Incorporar la incertidumbre de las encuestas. Este es el paso más complicado y más importante. Necesitamos estimar la precisión esperada de los sondeos en México. ¿De qué magnitud son los errores habituales? ¿Cómo de probable es que se produzcan errores de 2, 3 o 5 puntos? Para responder esas preguntas hemos estudiado cientos de encuestas en México y miles internacionales.
Calibrar los errores esperados. Primero he estimado el error de las encuestas en México. He construido una base de datos con encuestas de cinco elecciones desde 2000 —incluyendo las tres presidenciales. El error absoluto medio (MAE) de los promedios de encuestas en México ha rondado los 3 puntos por partido o candidato. Pero esos errores dependen al menos de dos cosas: del tamaño del candidato/partido y de la cercanía de las elecciones. Para tener en cuenta esos dos factores hemos recurrido a la base de datos de Jennings y Wlezien, recientemente publicada en Nature. Hemos analizado los errores de más de 4.100 encuestas en 241 elecciones de 19 países occidentales. Así hemos construido un modelo sencillo que estima el error MAE del promedio de votos estimado por las encuestas para cada partido, teniendo en cuenta: i) su tamaño (es más fácil estimar un partido que ronda el 5% en votos que uno que supera el 30%), y ii) los días que faltan hasta las elecciones (porque las encuestas mejoran al final).
Distribución. Para incorporar la incertidumbre al voto de cada partido en cada simulación utilizo uno distribución multivariable. Uso distribuciones t-student en lugar de normales para que tengan colas más largas (curtosis): eso hace más probable que sucedan eventos muy extremos. Las ventajas de esa hipótesis la explica Nate Silver. El nivel de curtosis lo he estimado con la base de datos. Luego defino la matriz de covarianzas de estas distribuciones para que i) la suma de los votos no sobrepase el 100% (una idea de Chris Hanretty), y ii) consideren correlaciones entre candidatos cercanos (tomando datos de duelos cara a cara y de segundas opciones). Por último, hay que escalar la amplitud de las matrices de covarianza para que las distribuciones de voto que resultan al final tengan el MAE y la amplitud esperados según la calibración.
Paso 3. Simular. El último paso consiste en ejecutar el modelo 20.000 veces. Cada iteración es una simulación de las elecciones con porcentajes de voto que varían según la distribución definida en el paso anterior. Los resultados en esas simulaciones permiten calcular las probabilidad que tiene cada candidato de ganar.
Por qué encuestas. El modelo se basa por entero en encuestas. Existe la percepción de que los sondeos no son fiables, pero a nivel nacional fallaron por pocos puntos incluso con Trump y con el Brexit. En otras elecciones recientes dieron menos que hablar porque estuvieron acertados (Francia, Países Bajos, País Vasco, Galicia, Cataluña). Pese a la creencia popular, lo cierto es que las encuestas no lo han hecho mal últimamente. Las encuestas raramente son perfectas, pero no existe una alternativa que haya demostrado mejor capacidad de predicción.
Fuente: El País



